
Hadoop技術已經無處不在。不管是好是壞,Hadoop已經成為大數據的代名詞。短短幾年間,Hadoop從一種邊緣技術成為事實上的標準。看來,不僅現在Hadoop是企業大數據的標準,而且在未來,它的地位似乎一時難以動搖。
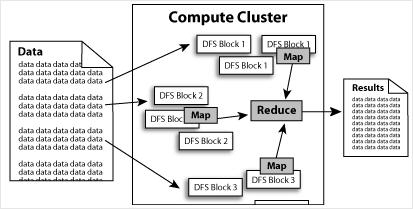
Hadoop的核心就是HDFS和MapReduce,而兩者隻是理論基礎,不是具體可使用的高級應用,Hadoop旗下有很多經典子項目,比如HBase、Hive等,這些都是基於HDFS和MapReduce發展出來的。要想了解Hadoop,就必須知道HDFS和MapReduce是什麼。
HDFS有著高容錯性的特點,並且設計用來部署在低廉的(low-cost)硬件上。而且它提供高傳輸率(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。
HDFS放寬了(relax)POSIX的要求(requirements)這樣可以流的形式訪問(streaming access)文件係統中的數據。
⒈高可靠性。Hadoop按位存儲和處理數據的能力值得人們信賴。
⒉高擴展性。Hadoop是在可用的計算機集簇間分配數據並完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。
⒊高效性。Hadoop能夠在節點之間動態地移動數據,並保證各個節點的動態平衡,因此處理速度非常快。
⒋高容錯性。Hadoop能夠自動保存數據的多個副本,並且能夠自動將失敗的任務重新分配。
Hadoop帶有用 Java 語言編寫的框架,因此運行在 Linux 生產平台上是非常理想的。Hadoop 上的應用程序也可以使用其他語言編寫,比如 C++。
1、存儲文件的時候需要指定存儲的路徑,這個路徑是HDFS的路徑。而不是哪個節點的某個目錄。比如./hadoop fs -put localfile hdfspat
一般操作的當前路徑是/user/hadoop比如執行./hadoop fs -ls .實際上就相當於./hadoop fs -ls /user/hadoop
2、HDFS本身就是一個文件係統,在使用的時候其實不用關心具體的文件是存儲在哪個節點上的。如果需要查詢可以通過頁麵來查看,也可以通過API來實現查詢。
 粘粘世界 (World of Goo)中文版
70.7M / 中文08-11
粘粘世界 (World of Goo)中文版
70.7M / 中文08-11
 孤單槍手之重臨(AlienShooter:Revisited)v1.0 英文版
21.6M / 英文05-01
孤單槍手之重臨(AlienShooter:Revisited)v1.0 英文版
21.6M / 英文05-01
 GARNET CRADLE Sugary Sparkle
482.1M / 日文10-16
GARNET CRADLE Sugary Sparkle
482.1M / 日文10-16
 nHancer v2.5.7遊戲配置工具
1.5M / 中文10-09
nHancer v2.5.7遊戲配置工具
1.5M / 中文10-09
 寶庫horad(HOARD)
382.8M / 英文11-27
寶庫horad(HOARD)
382.8M / 英文11-27
 dota6.72 test版本下載
7.5M / 英文04-21
dota6.72 test版本下載
7.5M / 英文04-21
 星際爭霸2DOTA0.9版(Defence of the Ancients0.9)測試
7.7M / 中文04-25
星際爭霸2DOTA0.9版(Defence of the Ancients0.9)測試
7.7M / 中文04-25
 星際爭霸2DOTA1.0(Defence of the Ancients1.0)測試版
1.7M / 英文04-25
星際爭霸2DOTA1.0(Defence of the Ancients1.0)測試版
1.7M / 英文04-25
 星際爭霸2DOTA帝國聖地風暴(SotIS)帝國聖地風暴
2.6M / 中文04-26
星際爭霸2DOTA帝國聖地風暴(SotIS)帝國聖地風暴
2.6M / 中文04-26
 Dota6.71b ai版6.71b ai地圖
7.6M / 中文04-29
Dota6.71b ai版6.71b ai地圖
7.6M / 中文04-29
 妻中蜜3全cg存檔
遊戲工具 / 28KB
下載
1
妻中蜜3全cg存檔
遊戲工具 / 28KB
下載
1
 SimplyCam DXF格式編輯器v2.4.0 綠色版
文件處理 / 2.0M
下載
2
SimplyCam DXF格式編輯器v2.4.0 綠色版
文件處理 / 2.0M
下載
2
 csgo空格鍵連跳腳本綠色免費版
遊戲工具 / 564KB
下載
3
csgo空格鍵連跳腳本綠色免費版
遊戲工具 / 564KB
下載
3
 LOL Dsx換膚小助手2016 最新過檢測版
遊戲工具 / 4KB
下載
4
LOL Dsx換膚小助手2016 最新過檢測版
遊戲工具 / 4KB
下載
4
 免費的SQLite3數據管理工具(SQLiteSpy)v1.9.9綠色版
編程軟件 / 1.9M
下載
5
免費的SQLite3數據管理工具(SQLiteSpy)v1.9.9綠色版
編程軟件 / 1.9M
下載
5
 魔獸7.2.5塞弗斯的秘密buff監控wa字符串
遊戲工具 / 1KB
下載
6
魔獸7.2.5塞弗斯的秘密buff監控wa字符串
遊戲工具 / 1KB
下載
6
 我的世界礦物透視MOD1.6.4-1.8集合版本
遊戲工具 / 889KB
下載
7
我的世界礦物透視MOD1.6.4-1.8集合版本
遊戲工具 / 889KB
下載
7
 易控王文檔加密軟件v2017官方版綠色免費版
文件處理 / 46M
下載
8
易控王文檔加密軟件v2017官方版綠色免費版
文件處理 / 46M
下載
8
 DNF9周年第十套天空時裝補丁
遊戲工具 / 1.6M
下載
9
DNF9周年第十套天空時裝補丁
遊戲工具 / 1.6M
下載
9
 魔獸7.3世界任務插件worldquesttracker
遊戲工具 / 1M
下載
10
魔獸7.3世界任務插件worldquesttracker
遊戲工具 / 1M
下載
10
140.5M / 09-05
 立即下載
立即下載
76.4M / 03-25
 立即下載
立即下載
55M / 06-05
 立即下載
立即下載
237.9M / 04-13
 立即下載
立即下載
900.9M / 03-02
 立即下載
立即下載
96.2M / 07-06
 立即下載
立即下載
311.2M / 07-06
 立即下載
立即下載
335M / 07-06
 立即下載
立即下載
200M / 07-06
 立即下載
立即下載
413.8M / 07-06
 立即下載
立即下載
768.9M / 08-19
 立即下載
立即下載
484.7M / 09-27
 立即下載
立即下載
165.4M / 09-05
 立即下載
立即下載
131.8M / 04-13
 立即下載
立即下載
195.6M / 03-03
 立即下載
立即下載
45.6M / 09-08
 立即下載
立即下載
665.2M / 07-06
 立即下載
立即下載
2.84G / 07-06
 立即下載
立即下載
93M / 07-06
 立即下載
立即下載
338.3M / 07-06
 立即下載
立即下載
892.4M / 08-18
 立即下載
立即下載 312M / 07-30
 立即下載
立即下載 1.38G / 07-26
 立即下載
立即下載 109.8M / 06-03
 立即下載
立即下載 142M / 01-08
 立即下載
立即下載 1.2M / 11-23
 立即下載
立即下載 548.8M / 04-13
 立即下載
立即下載 1.6M / 04-13
 立即下載
立即下載 1.48G / 03-18
 立即下載
立即下載 646.6M / 03-03
 立即下載
立即下載 404M / 08-18
 立即下載
立即下載 110.5M / 09-05
 立即下載
立即下載 33.4M / 09-05
 立即下載
立即下載 60M / 04-29
 立即下載
立即下載 254M / 04-25
 立即下載
立即下載 659M / 04-23
 立即下載
立即下載 1M / 12-26
 立即下載
立即下載 253.4M / 12-08
 立即下載
立即下載 253M / 12-08
 立即下載
立即下載 1.19G / 11-16
 立即下載
立即下載 115.9M / 08-19
 立即下載
立即下載 488.3M / 06-04
 立即下載
立即下載 369M / 09-22
 立即下載
立即下載 181.5M / 09-22
 立即下載
立即下載 201.2M / 09-05
 立即下載
立即下載 248.9M / 12-08
 立即下載
立即下載 248.9M / 12-08
 立即下載
立即下載 100.6M / 03-06
 立即下載
立即下載 148.9M / 03-06
 立即下載
立即下載 1.12G / 07-06
 立即下載
立即下載 126.7M / 02-04
 立即下載
立即下載 1.76G / 09-22
 立即下載
立即下載 1.92G / 04-17
 立即下載
立即下載 201.5M / 04-13
 立即下載
立即下載 7.31G / 07-01
 立即下載
立即下載 94.3M / 07-06
 立即下載
立即下載 2.48G / 07-06
 立即下載
立即下載 7.63G / 07-06
 立即下載
立即下載 1M / 07-06
 立即下載
立即下載 778.1M / 07-06
 立即下載
立即下載 1.30G / 08-19
 立即下載
立即下載 72M / 07-06
 立即下載
立即下載 548.7M / 07-06
 立即下載
立即下載 1.00G / 07-06
 立即下載
立即下載 9.13G / 07-06
 立即下載
立即下載 126.2M / 07-06
 立即下載
立即下載 72M / 07-06
 立即下載
立即下載 105.1M / 07-06
 立即下載
立即下載 132M / 07-06
 立即下載
立即下載 132M / 07-06
立即下載 























